 Section
Navigation
Section
Navigation
7. Technical Aspects
:Fundamental
7.1 Anatomy of Internet
7.2
Telecommunications
7.3 Wireless systems
7.4 Client Computers
7.5
Mobile Devices
7.6 Operating Systems
7.7 Computer Programs
7.8
Security: Applications
7.9 Browsers
7.10 Business Intelligence Systems
7.11 Cloud Computing
7.12
Databases
7.13 DTP Programs
7.14
eBook Readers
7.15 eMail Services
7.16 Expert Systems
7.17
Graphics Programs
7.18 Internet TV
7.19 Music & Video
7.20
Really Simple Syndication
7.21 Rich Media
7.22 Search Engines
7.23
Spreadsheets
7.24 Video Conferencing
7.25 Word Processing
:Corporate
Matters
7.26 Cluster Analysis
7.27 Neural Networks
7.28
Pricing Models
7.29 Realtime Systems
7.30 Regression Analysis
 7.27
Neural Network Analysis
7.27
Neural Network Analysis
Neural networks are computer programs that imitate
the neural networks of the brain in decision-making. At their simplest, there
is an input layer, a hidden layer and an output layer. The input layer can be
multiple, and many thousands of node can make up each layer, but typically a neural
network will have a single hidden layer, and each layer will consist of no more
than several hundred nodes — the larger the neural network, the longer it
takes to run. This node arrangement is virtual, simply a computer program that
continually changes the weightings of simulated links between nodes until the
network is trained properly. 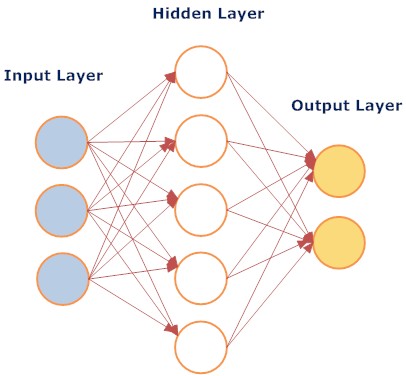
Neural networks learn from experience, being good at pattern recognition, generalization, and trend prediction. Though not fast, they are tolerant of imperfect data, and do not need you to select statistical formulas or know in advance which factors will be important. Neural networks are trained by repeatedly presenting examples to the network. Each example includes both inputs (information you would use to make a decision) and outputs (the resulting decision, prediction, or response). The network tries to learn from each of the examples in turn, calculating its output based on the inputs provided. If the network output doesn't match the target output, the network corrects the network by changing its internal connections. This trial-and-error process continues until the network reaches a specified level of accuracy. Once the network is trained and tested, you can give it new input information, and it will produce a prediction.
The key to designing a successful neural network is to clearly formulate the problem, and to collect lots of relevant data. Typically, you:
1. Divide your data into two batches, a large one
for training and a smaller one for testing.
2. Input your training data,
either manually or by importing a file in Lotus, Excel, dBase, text, etc.
3. Train your network, until either the entire training file has been memorized,
or until the network's performance on the testing file reaches the optimum you
have set.
4. Test your network, i.e. show it new data (i.e. testing data)
and check the output. If the results are good, your network is ready to use. If
not, you have to get more or better data, or redesign your network.
You may want a program like NeuroXL that hides most of the complexities (though it does allow you change the training parameters) or one like BrainMaker where you can see the output of each stage and tweak the parameters accordingly.
Neural network programs generally come with an extensive manual, and case studies to stimulate ideas.
Processing Data in Real Time
Neural networks take time to produce predictions, and are not ideally suited to processing data in real time. But if you did want a site that was continually extracting data from customers, feeding it through a neural network and supplying customers with appropriate webpages, then the coding for neural networks is available in most computer language libraries. Toby Segaran's Programming Collective Intelligence provides a worked example and some of the Python code.
Case study: Direct Mailing
Microsoft used BrainMaker neural network software to maximize returns on their direct mailing campaigns. Each year, the company sent out about 40 million pieces of direct mail to 8.5 million registered customers. Most of these direct mailings were aimed at getting people to upgrade their software or buy related products. The first mailing usually included everyone in the database, but the second was only sent to individuals most likely to respond.
Company spokesman Jim Minervino, when asked how BrainMaker neural network software had maximized their returns on direct mail, said, 'Prior to using BrainMaker, an average mailing would get a response rate of 4.9%. By using BrainMaker, our response rate has increased to 8.2%. The result is a huge dollar difference that brings in the same amount of revenue for 35% less cost! To get a BrainMaker neural network to maximize returns on direct mail, several variables were fed into the network. The first objective was to see which variables were significant and to eliminate those that were not. Some of the more significant variables were:
1. Date of last purchase —
the last time something was bought and registered, calculated in number of days.
It is a known fact that the more recently you've bought something, the better
the chance you're going to buy more.
2. Date of first purchase — the
date an individual made their first purchase. This is a measure of loyalty. The
longer you've been a loyal customer, the better the chance is you're going to
buy again.
3. Number of products bought and registered.
4. Value of
the products bought and registered (at standard reselling price).
5. Number
of days between the time the product came out and when it was purchased. Research
has shown that people who tend to buy things as soon as they come out are the
key individuals to be reached.
6. Additional variables include information
taken from the registration card including yes/no answers to various questions
— scored with either a one or zero — areas of interest like recreation,
personal finances, and such personal information as age, and whether an individual
is retired or has children.
Microsoft also purchased data regarding
the number of employees, place of employment, as well as sales and income data
about that business. The neural network was tested on data from twenty campaigns
with known results not used during training.
Prior to training, the information taken from the response cards was put into a format the network could use, and yes/no responses were converted to numeric data. Minimums and maximums were also set on certain variables. Initially, the network was trained with about 25 variables. To make sure the data was varied, it was taken from seven or eight campaigns and represented all aspects of the business including the Mac and Windows sides, from high and low price point products. The model trained for about seven hours before it stopped making progress. At that point, variables that didn't have a major impact were eliminated. This process was repeated.
The currently-trained model is based on nine inputs. Jim Minervino explained some of the other training considerations: 'During training I used modify size, prune neurons and add neuron, also experimenting with recurrent operations, though in the net model we ended up using the default.' The output was a quantitative score from zero to one indicating whether an individual should receive or should not receive a second mailing. Minervino found that anybody scoring above 0.45 was more responsive to the mailing than anybody below.
 Questions
Questions
1. Explain briefly how neural networks operate.
2. What sorts of
problems are they used to solve?
3. Provide five examples of their successful
use.
4. Describe in detail their use in Microsoft's direct mailing study.
 Sources
and Further Reading
Sources
and Further Reading
1. Information Theory, Inference,
and Learning Algorithms. David MacKay. 2003. Inference.
Includes neural networks and their theory. Hardback $60 but free as PDF download.
2. Programming Collective Intelligence: Building Smart Web 2.0 Applications
by Toby Segaran. O'Reilly. August 2007. Includes specimen code in Python.
3. An Introduction to Neural Networks by Kevin Gurney. CRC Press. August
1997.
4. Designing Neural Networks with BrainMaker. BrainMaker.
Introductory background for BrainMaker users.
5. Maximize Returns on Direct
Mail with BrainMaker Neural Network Software. BrainMaker.
Other case studies on site.
6. Easynn.
Fully-featured neural network software system that runs under Windows.
7.
BrainMaker. Professional's
choice of neural network system.
8. NeuroXL.
Neural network tool: runs with MS Excel.